
01. 내장 함수
01. SQL 내장 함수
SQL 내장 함수는 상수나 속성 이름을 입력 값으로 받아 단일 값을 결과로 반환한다.
모든 내장 함수는 최초에 선언 될 때 유효한 입력 값을 받아야 한다. (만약 선언에 위배된 값이 입력되면 질의는 실행을 중지하고 에러 메세지를 출력한다.)
숫자 함수

문자 함수

날짜, 시간 함수

02. NULL 값 처리
NULL 값은 아직 지정되지 않은 값을 말하므로 0, 빈문자, 공백 등과 다른 특별한 값임을 명심해야 한다.
NULL 값에 대한 연산과 집계 함수
집계 함수를 사용할 때 NULL값이 포함된 행에 대하여 다음과 같은 주의가 필요하다!
- NULL + 숫자 연산의 결과는 NULL이다.
- 집계 함수를 계산할 때 NULL이 포함된 행은 집계에서 빠진다.
- 해당되는 행이 하나도 없을 경우, snum, avg 함수의 결과는 NULL count 함수의 결과는 0이다.
NULL 값 확인하기 - IS NULL, IS NOT NULL
NULL값을 찾을 때는 =연산자가 아닌 IS NULL을 사용한다.
NULL이 아닌 값을 찾을 떄는 <> 연산자가 아닌 IS NOT NULL을 사용한다.
Mybook
bookid price
| 1 | 10000 |
| 2 | 20000 |
| 3 | NULL |
select *
from MyBook
where price Is Null; // price 가 NULL인지 확인
IFNULL 함수
IFNULL함수는 NULL값을 다른 값으로 대치하여 연산하거나 다른 값으로 출력하는 함수다. 즉, NULL값을 임의의 다른 값으로 변경할 수 있다.
IFNULL(속성, 값) // 속성 값이 NULL이면 '값'으로 대체한다.
03. 행 번호 출력
MySQL에서 변수는 이름 앞에 @ 기호를 붙이며 치환 문에는 SET과 := 기호를 사용한다.
-- 고객 목록에서 고객번호, 이름, 전화번호를 앞의 두 명만 보이시오.
set @seq:=0;
select (@seq:=@seq+1) '순번', custid, name, phone
from customer
where @seq < 2;
02. 부속 질의
부속 질의: 하나의 SQL 문 안에 다른 SQL 문이 중첩된 질의
일반적으로 데이터의 양이 많은 경우 대체로 조인을 이용하는 방법보다 부속 질의를 이용하는게 성능상 좋다.
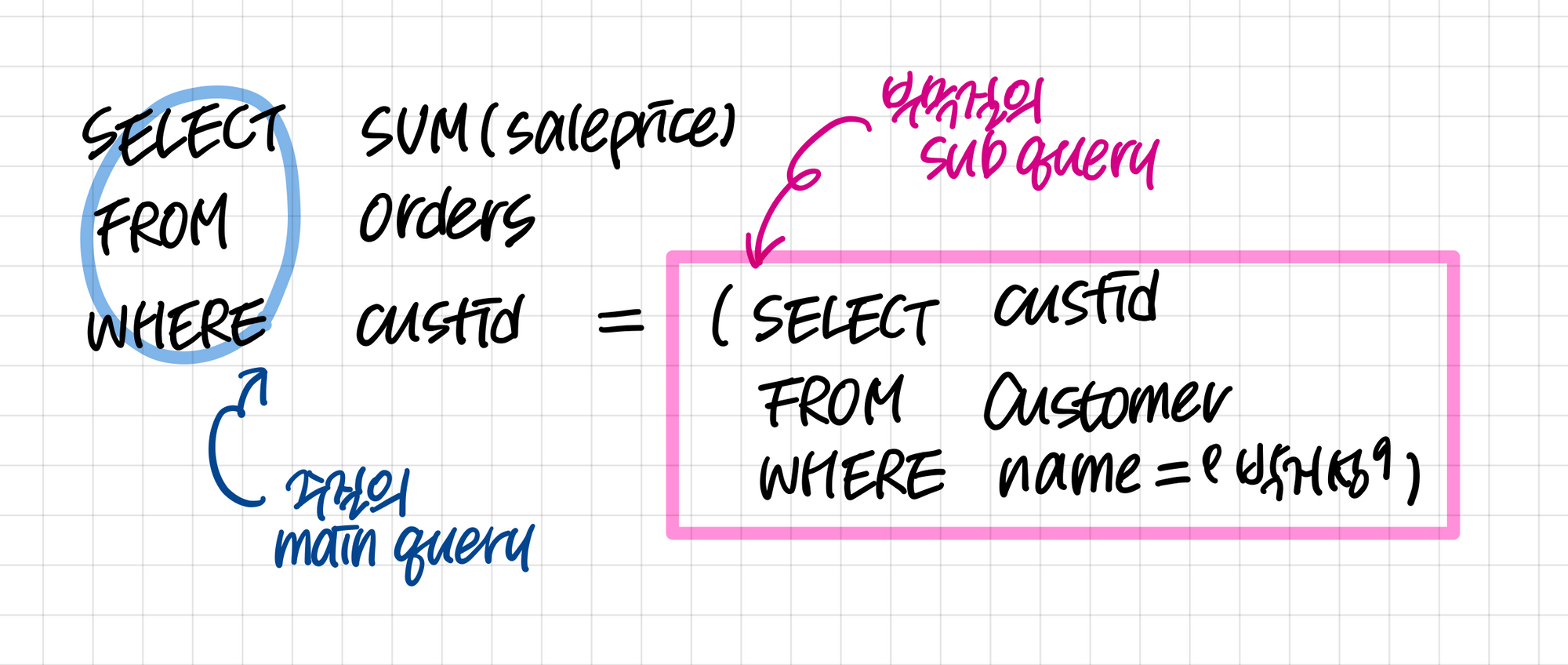
스칼라 부속질의 - select 부속질의
부속 질의의 결과 값을 단일 행, 단일 열의 스칼라 값으로 반환한다.
결과 값이 다중 행, 열이라면 에러를 출력한다. 결과가 없는 경우에는 NULL을 출력한다.
스칼라 부속 질의는 원칙적으로 스칼라가 들어갈 수 있는 모든 곳에 사용 가능하다.
인라인 뷰 - From부속질의
(여기서 뷰view는 기존 테이블로부터 일시적으로 만들어진 가상의 테이블을 말한다.)
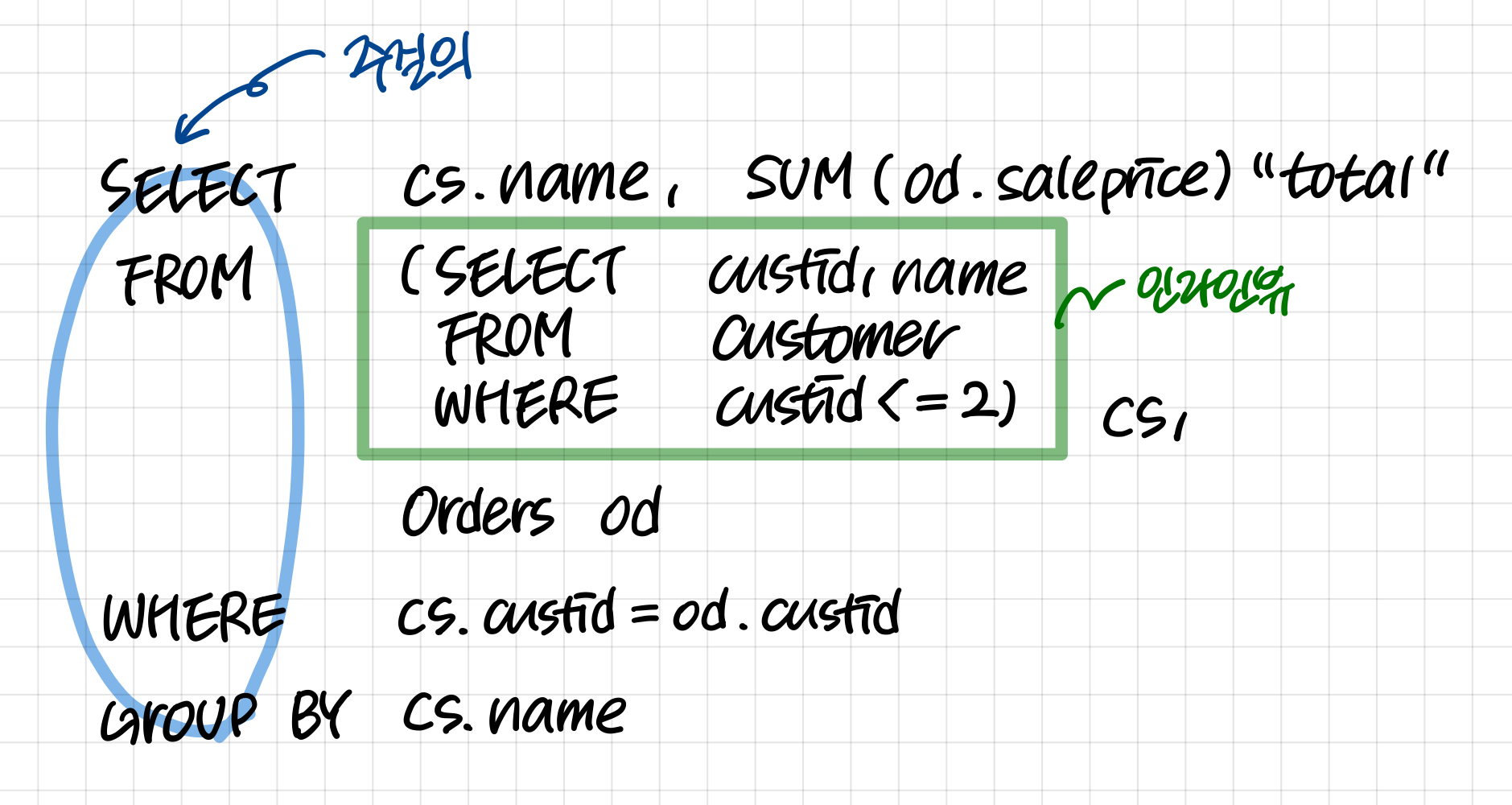
중첩 질의(부속질의) - Where 부속 질의
연산 결과에 따라 where절의 조건이 참인지 거짓인지 확인하여 참인 경우 주질의의 해당 행을 출력한다.
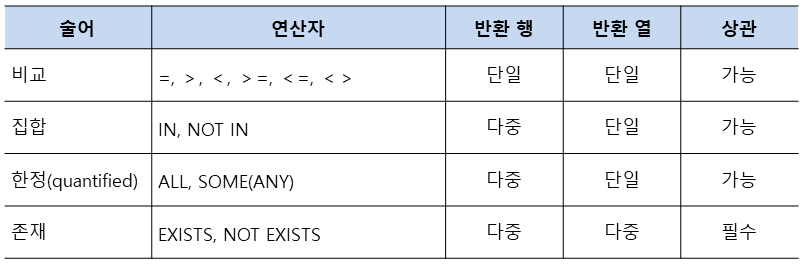
IN, NOT IN
: 제공한 결과 집합에 있는 지 확인하는 역할
-- 대한민국에 거주하는 고객에게 판매한 도서의 총 판매액을 구하시오.
select sum(saleprice) 'total'
from orders
where custid In (
select custid
from customer
where address like '%대한민국%'
);
ALL, AOME(ANY)
: 비교 연산자와 함께 사용하며 ALL은 모든, SOME은 어떠한(최소한 하나라도)이라는 의미를 가진다.
scalar_expression {비교연산자 ( )}
{ALL | SOME | ANY} (부속질의)
-- 3번 고객이 주문한 도서의 최고 금액보다 더 비싼 도서를 구입한 주문의 주문번호와 판매금액을 보이시오.
select orderid, saleprice
from orders
where saleprice > ALL (
select saleprice
from orders
where custid='3'
);
EXISTS, NOT EXISTS
: 데이터의 존재 유무를 확인하는 연산자이다.
WHERE [NOT] EXISTS (부속질의)
-- Exists 연산자를 사용하여 대한민국에 거주하는 고객에게 판매한 도서의 총 판매액을 구하시오.
select sum(saleprice) 'total'
from orders od
where Exists (
select *
from customer cs
where address like '%대한민국%' and cs.custid = od.custid
);
03. 뷰
: 하나 이상의 테이블을 합하여 만든 가상의 테이블
: 실제 SQL 문에서 테이블과 동일하게 사용할 수 있는 데이터 베이스 개체
뷰의 장점
- 편리성, 재사용성
- 보안성
- 독립성
01. 뷰의 생성
뷰는 사용자가 직접 정의하는 과정을 거치는데, 뷰의 정의를 뷰의 생성이라고도 한다.
뷰이름은 생성할 뷰의 이름을, 열이름은 뷰에서 사용할 열의 이름을 말한다.
열 이름과 SELECT 문에서 추출하는 속성은 일대일로 대응된다.
CREATE VIEW 뷰이름[(열이름 [ ,,,, n])]
AS SELECT 문
-- 주소에 '대한민국'을 포함하는 고객들로 구성된 뷰를 만들고 조회하시오.
create view vw_customer
as select *
from customer
where address like '%대한민국%';
select *
from vw_customer;
02. 뷰의 수정
CREATE OR REPLACE 뷰이름[(열이름 [ ,,,, n])]
AS SELECT 문
-- vw_customer의 데이터중 대한민국 고객을 영국 주소로 가진 고객으로 변경하시오.
create or replace view vw_customer(custid, name, address)
as select custid, name, address
from customer
where address like '%영국%';
select *
from vw_customer;
03. 뷰의 삭제
DROP VIEW 뷰이름
04. 인덱스
01. 데이터베이스의 물리적 저장
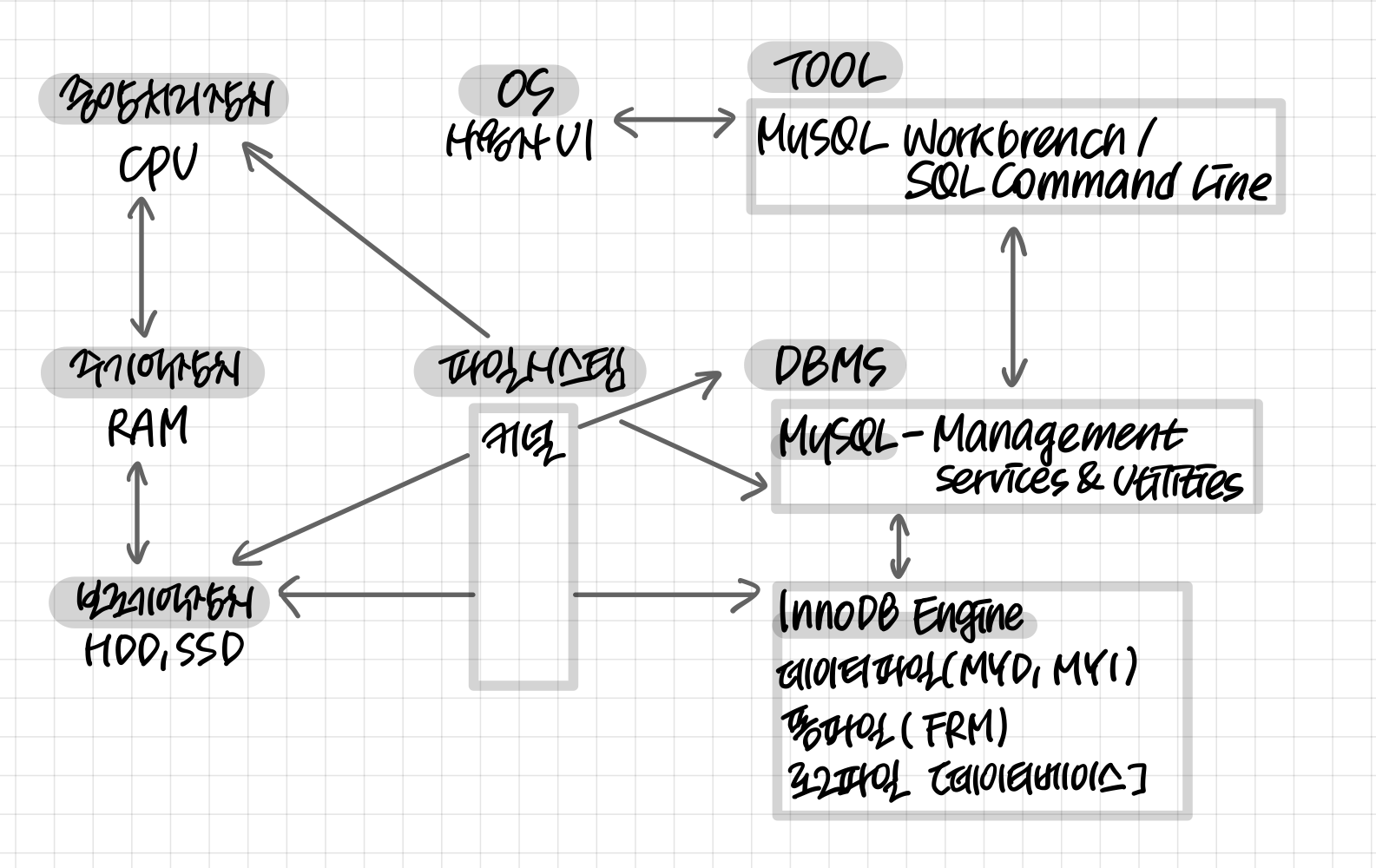
✨실제 데이터가 저장되는 곳이 보조 기억 장치라는 점
02. 인덱스와 B-tree
데이터 베이스에서 인덱스란 원하는 데이터를 빨리 찾기 위해 투플의 키 값에 대한 물리적 위치를 기록해준 자료구조이다.
일반적인 RDBMS의 인덱스는 대부분 B-tree구조로 되어 있다.
B-tree (balanced-tree) 이란?
데이터의 검색 시간을 단축하기 위한 자료구조로 바이어가 고안하였다.
루트 노드, 내부 노드, 리프 노드로 구성되며, 러프 노드가 모두 같은 레벨에 존재하는 균형 트리이다.
B-tree의 각 노드는 키 값과 포인터를 가진다. 키 값은 오름차순으로 저장되어 있으며 키 값 좌우에 있는 포인터는 각각 키 값보다 작은 값과 큰 값을 가진 다음 노드를 가리킨다. 따라서 키 값을 비교하여 다음 단계의 노드를 쉽게 찾을 수 있다.
B-tree는 키 값이 새로 추가되거나 삭제될 경우 동적으로 노드를 분할하거나 통합하여 항상 균형 상태를 유지한다.
03. MySQL 인덱스
클러스터 인덱스
연속된 키 값의 레코드를 묶어서 같은 블록에 저장하는 방법으로 테이블당 하나만 생성할 수 있다. B-tree 인덱스의 리프 노드에서 페이지의 주소 값 대신 테이블의 열 자체가 저장되는 형태이다.
보조 인덱스
속성의 값으로 B-tree 인덱스를 구성하여 리프 노드의 각 행은 해당 페이지의 주소 값을 저장한다.
MySQL 인덱스
MySQL에서는 클러스터 인덱스와 보조 인덱스가 보통 같이 사용된다.
04. 인덱스의 생성
인덱스 생성 시 고려사항
- 인덱스는 WHERE 절에 자주 사용되는 속성이어야 한다.
- 인덱스는 조인에 자주 사용되는 속성이어야 한다.
- 단일 테이블에 인덱스가 많으면 속도가 느려질 수 있다.(테이블 당 4~5개 권장)
- 속성이 가공되는 경우 사용하지 않는다.
- 속성의 선택도가 낮을 때 유리하다.(속성의 값이 모든 다른 경우 유리하다.)
CREATE [UNIQUE] INDEX [인덱스이름]
ON 테이블이름 (컬럼 [ASC | DESC] [{, 컬럼 [ASC | DESC]} ...[])[;]
MySQL이 생성된 인덱스를 활용하여 SQL문을 처리하는지 확인하려면
[MySQL Workbench]-[Query]-[Explain Current Statement] 를 누르면 실행 계획이 나타나면서 인덱스를 활용하여 결과를 출력하는 과정을 보여줄 수 있다.
05. 인덱스의 재구성과 삭제
데이터 변경이 잦으면 단편화 현상(삭제된 레코드의 인덱스 값 자리가 비게 되는 상태)이 나타나는데, 이럴 경우 아래의 ANALYZE문을 이용하여 인덱스를 다시 생성해준다.
ANALYZE TABLE 테이블이름;
'데이터분석(DataBase) > MySQL' 카테고리의 다른 글
| MySQL로 배우는 데이터베이스 개론과 실습 내용정리 - Chapter 05 (0) | 2022.08.25 |
|---|---|
| MySQL로 배우는 데이터베이스 개론과 실습 답안 - Chapter 04 (0) | 2022.08.25 |
| MySQL로 배우는 데이터베이스 개론과 실습 답안 - Chapter 03 (0) | 2022.08.25 |
| MySQL로 배우는 데이터베이스 개론과 실습 답안 - Chapter 02 (0) | 2022.07.17 |
| MySQL로 배우는 데이터베이스 개론과 실습 답안 - Chapter 01 (0) | 2022.07.09 |



